CLEPS architecture¶
What is a cluster?¶
A computing cluster is a group of interconnected computers. The typical architecture is composed of:
a login node
several computing nodes
storage nodes
a network
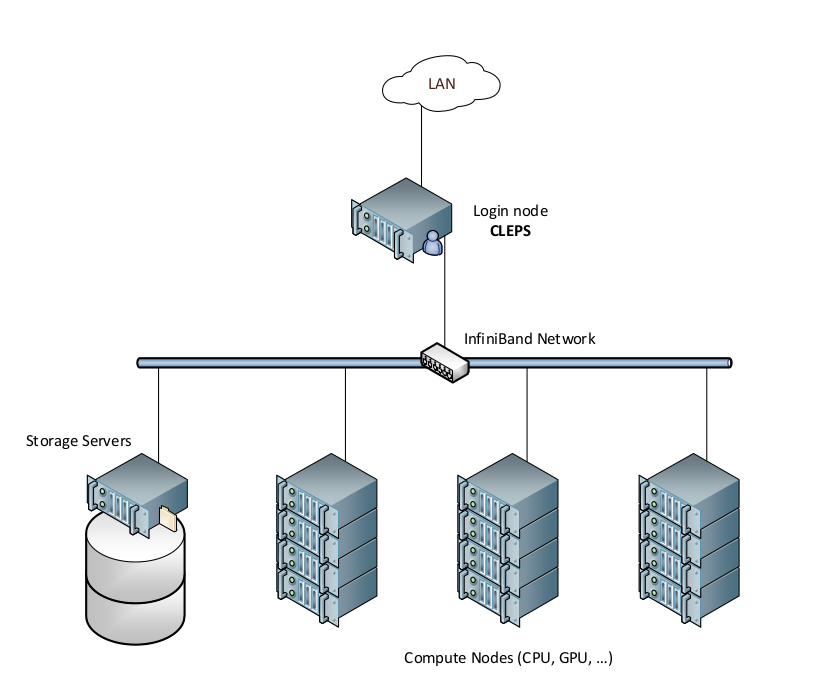
In the case of CLEPS, users connect to the login node and schedule their jobs from there. The scheduler (also named ressource manager) is responsible for finding available computing resources and starting jobs using them.
CLEPS Compute nodes¶
All the nodes are running CentOS 7.9 with linux kernel 3.10.0.
id |
number
of nodes
|
RAM |
/localdisk
|
processor
type
|
hyper
threading
|
total
number
of cores
|
average
memory
per core
|
Features |
InfiniBand
Network
|
GPU/node |
CPUs/GPU * |
|---|---|---|---|---|---|---|---|---|---|---|---|
node0[01-20] |
20 |
192 GB
2667 MHz
|
220 GB
6GB/s
SSD
|
2x Cacade Lake
Intel Xeon 5218
16 cores, 2.4GHz
|
yes |
640 |
6GB |
hyperthreading,192go, cascadelake |
100Gb/s |
None |
|
node0[21-24] |
4 |
176 GB
2400 MHz
|
600 GB
6GB/s
HDD
|
2x Intel Xeon
E5-2650 v4
12 cores
|
yes |
96 |
7.3GB |
hyperthreading,176go, broadwell |
56Gb/s |
||
node0[25-28] |
4 |
128 GB
2667 MHz
|
800 GB
6GB/s
HDD
|
2x Skylake
Intel Xeon 5118
12 cores
|
yes |
96 |
5.3GB |
hyperhtreading,128go, skylake |
100Gb/s |
||
node0[29-40] |
8 |
192 GB
2400 MHz
|
800 GB
6GB/s
HDD
|
2x broadwell
xeon e5-2650 v4
12 cores
|
yes |
288 |
8GB |
hyperthreading,192go, broadwell |
56Gb/s |
||
node0[41-44] |
4 |
256 GB
3200 MHz
|
370 GB
6GB/s
SSD
|
2x AMD EPIC 7352
24 cores, 2.3GHz
|
yes |
192 |
5.3GB |
hyperthreading,amd,256go |
100Gb/s |
||
node0[45-48] |
4 |
128 GB
2133 MHz
|
800 GB
6GB/s
HDD
|
2x broadwell
xeon e5-2695 v3
14 cores
|
yes |
112 |
4.6GB |
hyperthreading,128go, broadwell |
56Gb/s |
||
node0[49-56] |
8 |
128 GB
2400 MHz
|
800 GB
6GB/s
HDD
|
2x broadwell
xeon e5-2695 v4
18 cores
|
no |
288 |
3.6GB |
nohyperthreading,128go, broadwell |
56Gb/s |
||
mem001 |
1 |
3 TB
1333 MHz
|
200 GB
6GB/s
HDD
|
4x Intel Xeon
E7-4860 v2
12 cores, 2.6-3.2GHz
|
no |
48 |
62.5GB |
nohyperthreading,3to |
56Gb/s |
||
gpu001 |
1 |
192 GB
2667 MHz
|
3.8 TB
12GB/s
SSD
|
2x Cascade Lake
Intel Xeon 5217
8 cores, 3-3.7GHz
|
no |
16 |
12GB |
nohyperhtreading,192to, v100 |
100Gb/s |
2x Nvidia
V100 32GB
|
8 |
gpu00[2-3] |
2 |
192 GB
3200 MHz
|
1.5 TB
12GB/s
NVME
|
2x AMD EPIC 7302
16 cores, 3-3.3GHz
|
yes |
64 |
6GB |
hyperthreading,192go, rtx6000 |
100Gb/s |
3x Nvidia
RTX6000 24GB
|
16 |
gpu00[4-5] |
2 |
96 GB
2400 MHz
|
200 GB
6GB/s
HDD
|
2x Skylake
Intel Xeon 5118
12 cores, 2.3-3.2GHz
|
yes |
48 |
4GB |
hyperthreading,96go, gtx1080ti |
56Gb/s |
4x Nvidia
GTX 1080Ti
|
12 |
gpu00[6-9] |
4 |
192 GB
3200 MHz
|
1.5 TB
12GB/s
NVME
|
2x AMD EPIC 7302
16 cores, 3-3.3GHz
|
yes |
128 |
6GB |
hyperthreading,192go, rtx8000 |
100Gb/s |
3x Nvidia
RTX8000 48GB
|
16 |
gpu011 |
1 |
128 GB
2400 MHz
|
200 GB
6 GB/s
HDD
|
2x Intel Xeon
E5-2650L v4
14 cores, 1.7-2.5GHz
|
yes |
28 |
4GB |
hyperthreading,128go, rtx2080ti |
56Gb/s |
4x Nvidia
RTX2080ti
12GB
|
6 |
gpu01[2-3] |
2 |
256 GB
3200 MHz
|
3.6 GB
12 GB/s
HDD
|
AMD EPYC 7543P
32 cores, 2.8GHz
|
yes |
56 |
4GB |
hyperthreading,256go, a100 |
100Gb/s |
4x Nvidia
A100
80GB
|
14 |
- *
Maximum number of cpu you can allocate with
--cpus-per-taskper allocated GPU card.
You’ll notice that some nodes have the hyperthreading activated. It means that you can allocate twice as many logical cores (threads) as there are physical cores on these nodes. For example for node001 to node020, you can allocate a maximum of 64 logical cores.
CLEPS Partitions¶
When you submit a job with srun or sbatch, you submit it into a
partition (like a queue). Nodes into a partition share common purpose or
configuration. To specify a partition when submitting a job, add the -p or
--partition option, followed by the name of the partition.
# To submit your job into cpu_homogen partition
srun -N 2 -p cpu_homogen <myjob>
$ cat <my_batch_script>.batch
#!/bin/bash
#SBATCH --partition=cpu_homogen
...
If none is specified, you job will run in the default partition cpu_devel.
partition
name
|
nodes |
jobs max
duration
|
purpose/configuration
|
|---|---|---|---|
cpu_devel |
node021-056 |
1 week |
Tests, compilations
and small jobs
|
cpu_homogen |
node001-020 |
1 week |
Homogeneous set
of nodes. Suited
for scaling studies
of MPI jobs
|
gpu |
gpu001-009, gpu01[1-3] |
2 days |
Nodes equiped
with GPUs
|
mem |
mem001 |
2 days |
Large memory node |
*almanach |
gpu009 |
2 days |
GPU node, ALMANACH
priority
|
*willow |
gpu01[2-3] |
2 days |
GPU node, WILLOW
priority
|
Warning
Projects have the possibility to buy computing resources and to include them into the CLEPS infrastructure. They benefit from the whole infrastructure and mechanisms such as scheduling. They can also benefit a priorirty access on their resources, while letting them accessible to users from other projects when not used. This Slurm mechanism is known as job preemption.
Such resources are therefore present in two different partitions. The generic one that makes them available to everyone, and a higher priority one, only available to the members of the project that funded the resources. Such higher priority partition are marked with a * in the table above.
The gpu partition is currently the only one concerned. Be aware that
submitting in this partition could start your job on a proprietary
resource, also included in either the almanach or willow partition.
If you don’t want to take the risk of beeing preempted by a higher priority
job, you can explicitely exclude proprietary nodes from your allocation
request with the --exclude option.
Example:
srun -p gpu --exclude=gpu009,gpu01[2-3] ...
will exclude nodes gpu009, gpu012, gpu013 from your allocation.
If you belong to a team that benefit a prioritary access to some hardware, you have to specify both your partition AND account. I.e. for the members of ALMANACH team:
srun -p almanach -A almanach [options] <my_script_name>
Node features¶
In the table CLEPS Compute nodes, you’ll notice a column Features. This
column ensure the possibility to target nodes with certain caracteristics
in a partition.
Example:
You want to target nodes with AMD processors in the cpu_devel partition (default partition):
srun --constraint=amd ...
See the Slurm documentation for more information.
CLEPS Storage¶
The /home path¶
Your /home path is the prefered place to compile your code and
do small development tasks. It is backuped so it also a good place to store
important data. It is accessible with the $HOME environment variable.
Capacity and quotas
This partition is 9TB xfs filesystem and your disk space quota is set at 100GB.
To check your disk usage:
cd
du -sh .
The /scratch path¶
The scratch partition is a Lustre parallel filesystem and thereby designed to support large-file parallel IO. It is not backuped so it is not the right place to leave important data. It is accessible with the $SCRATCH environment variable.
Capacity and quotas
There are currently 500To available and a project quota of 20To is applied to each GID(=Team/EPI/service). If you need more space, you can contact directly the support via the helpdesk.
To check your project quota status:
# First, get your project ID
grep <group> /etc/lustre-projectid-gid | cut -c1
lfs quota -ph <project ID> /scratch
Lustre offers many tuning parameters to increase performances even
for small files. Check the File striping page to know how to tune
your /scratch tree.
Two special folders are available on the /scratch partition:
/scratch/_projets_/<user_main_group>, a folder shared by all the members of a project, accessible with the $PROJECT environment variable.
/scratch/_public_, a read-only folder accessible to every user. It can be used to store large data shared by several projects. An explicit demand must be done for the admin to write the data. It is accessible with the variable $PUBLIC.
The /local path¶
As the name suggests, this place is local to each node. It can be accessed only while a job is running with the variable $TMP_DIR. You can see how much space is available on each node in the CLEPS Compute nodes section.
Warning
This folder (/local) is a temporary storage solution, available at the scale
of a running job. Once your job is over, all your data are erased.